
Pada tahun 2024, aku dan tiga kolega dari University of Auckland, Universitas Pendidikan Indonesia, dan SMA Negeri 7 Yogyakarta merevisi buku teks kami, baik buku siswa maupun buku panduan guru. Dalam edisi revisi buku-buku tersebut, kami mencoba untuk mempromosikan tema Tujuan Pembangunan Berkelanjutan.
Salah satu aktivitas pembelajaran dalam edisi revisi tersebut adalah pemodelan keanekaragaman spesies tanaman berpohon di Kepulauan Raja Ampat. Dengan aktivitas pembelajaran ini, peserta didik diharapkan dapat menggunakan berbagai macam fungsi matematika untuk melakukan pemodelan serta menginterpretasi dan mengevaluasi model-model yang mereka hasilkan. Tak hanya itu, mereka juga diharapkan menyadari betapa kayanya bumi Kepulauan Raja Ampat.
Di artikel ini, aku akan bercerita tentang bagaimana menemukan data keanekaragaman hayati di Kepulauan Raja Ampat tersebut. Selain itu, aku juga akan mendemonstrasikan bagaimana mengolah dan memodelkan data tersebut dengan model linear maupun nonlinear.
Petulangan Menemukan Data
Salah satu hobiku adalah membaca. Meskipun bidang pekerjaanku adalah Pendidikan Matematika, tak jarang aku “tersesat” dan membaca berbagai bahan bacaan di luar bidang itu. Suatu ketika, aku menemukan sebuah artikel menarik di Ecography. Artikel yang dikarang oleh tim peneliti dari University of Göttingen, Universitas Papua, dan University of South Australia tersebut membahas tentang dampak perbedaan pengambilan sampel terhadap hubungan antara keanekaragaman spesies tanaman berkayu dan luas pulau-pulau kecil di Kepulauan Raja Ampat.
Menurutku artikel tersebut menarik. Namun, artikel tersebut tidak melampirkan data mentah yang digunakan. Oleh karena itu, aku langsung berkirim surel ke salah satu pengarangnya untuk meminta data mentahnya dan sekalian meminta izin untuk menggunakannya sebagai bahan ajar ke dalam buku-buku kami. Dengan ramah pengarang tersebut menunjukkan sebuah artikel yang memuat data mentah tersebut. Ia juga dengan senang memberikan izin penggunaan data tersebut asalkan dibarengi dengan pemberian atribusi yang tepat.
Data mentah yang aku perlukan letaknya ada di bagian lampiran artikel tersebut. Agar pembahasannya nanti sederhana, kita akan menggunakan data dalam bagian Suppl. material 1: Island Data saja. Kita nanti hanya akan mengolah data yang terkait dengan variabel luas pulau dan banyaknya spesies tanaman berkayu dalam pulau tersebut untuk memodelkan hubungan antara kedua variabel itu.
Selain hubungan antara luas pulau dan banyaknya spesies, data dalam artikel tersebut juga memungkinkan untuk dilakukan analisis sampai level transek dan subtransek. Analisis tentang transek dan subtransek tersebut pada umumnya digunakan untuk mengidentifikasi kepadatan spesies dalam pulau-pulau yang ada. Analisis pada level transek dan subtransek tersebut tidak dilakukan dalam artikel ini. Jika pembaca ingin mengetahui analisis semacam itu, silakan kunjungi aplikasi Shiny yang telah aku kembangkan. Aplikasi inilah yang digunakan sebagai bahan ajar penunjang dalam buku-buku yang kami revisi.
Menjelajah Data
Petualangan kita lanjutkan. Karena data sudah ada, sekarang kita siap untuk mengeksplorasinya dengan R. Pertama-tama, kita panggil paket yang diperlukan. Paket {tidyverse} kita gunakan untuk mengimpor, mengolah, dan memvisualisasikan data. Paket {ggtext} kita gunakan untuk menyesuaikan label/teks pada diagram yang akan kita buat nantinya.
Agar datanya nanti mudah kita impor, aku unduh fail data tersebut, kemudian aku hapus bagian yang tidak kita perlukan (seperti keterangan fail dan deskripsi variabelnya) dan aku simpan kembali menjadi fail csv. Fail data yang baru tersebut dapat diakses di tautan ini.
Kita impor data tersebut dengan fungsi read_csv(). Untuk melihat gambaran umum data tersebut, kita dapat menggunakan fungsi glimpse().
data_pulau <- read_csv("https://raw.githubusercontent.com/jelajahstatid/jelajahstatid.github.io/main/pos/2024-08-keanekaragaman-hayati-raja-ampat/data/oo_444807.csv")
glimpse(data_pulau)Rows: 60
Columns: 12
$ island_ID <chr> "GB1", "GB2", "GB3", "GB4", "GB5", "GB6", "GB7", "G…
$ island_coordinates <chr> "-0.520461, 130.580800", "-0.517484, 130.575020", "…
$ island_area <dbl> 4774.04, 7.29, 2329.91, 8.06, 20.27, 316.83, 1575.2…
$ island_perimeter <dbl> 303.14, 10.24, 184.23, 11.33, 16.60, 85.11, 149.77,…
$ distance_Gam <dbl> 59.30, 56.65, 172.07, 191.69, 136.06, 381.77, 344.6…
$ buffer_area_1000m <dbl> 146.90, 71.06, 45.80, 44.91, 47.01, 33.60, 36.22, 5…
$ tree_basal_area <dbl> 17.49, 0.95, 15.86, 0.87, 6.65, 20.04, 14.86, 20.65…
$ species_number <dbl> 18, 1, 17, 1, 2, 8, 12, 13, 18, 5, 9, 14, 10, 11, 9…
$ soil_depth_mean <dbl> 11.40, 0.00, 3.72, 0.00, 0.00, 3.94, 9.77, 12.74, 0…
$ leaf_litter_cover <dbl> 66.4, 0.0, 96.0, 0.0, 0.0, 60.0, 93.0, 78.0, 67.0, …
$ no_transects <dbl> 5, 0, 4, 0, 0, 2, 4, 4, 4, 1, 3, 4, 2, 2, 1, 0, 0, …
$ no_plots <dbl> 25, 1, 20, 1, 1, 10, 20, 20, 20, 5, 15, 20, 10, 10,…Data tersebut memuat 60 baris dan 12 kolom. Dari keduabelas kolom tersebut, kita hanya akan menganalisis dua di antaranya, yaitu island_area (luas pulau dalam m2) dan species_number (banyaknya spesies). Untuk itu, kita pilih kedua variabel tersebut dengan fungsi select(). Kita ganti nama kedua variabel tersebut menjadi luas_pulau dan banyak_spesies dengan fungsi rename().
data_pulau <- data_pulau |>
select(island_area, species_number) |>
rename(
luas_pulau = island_area,
banyak_spesies = species_number
)
head(data_pulau)# A tibble: 6 × 2
luas_pulau banyak_spesies
<dbl> <dbl>
1 4774. 18
2 7.29 1
3 2330. 17
4 8.06 1
5 20.3 2
6 317. 8Sekarang kita mendapatkan data_pulau yang lebih sederhana dan rapi. Kita lihat distribusi luas_pulau-nya seperti apa. Perhatikan Gambar 1.
data_pulau |>
ggplot(aes(x = luas_pulau)) +
geom_histogram(
fill = "#427D9D",
color = "white"
) +
theme_minimal() +
theme(
axis.title.x = element_markdown()
) +
labs(
x = "Luas pulau (m^2^)",
y = "Frekuensi"
)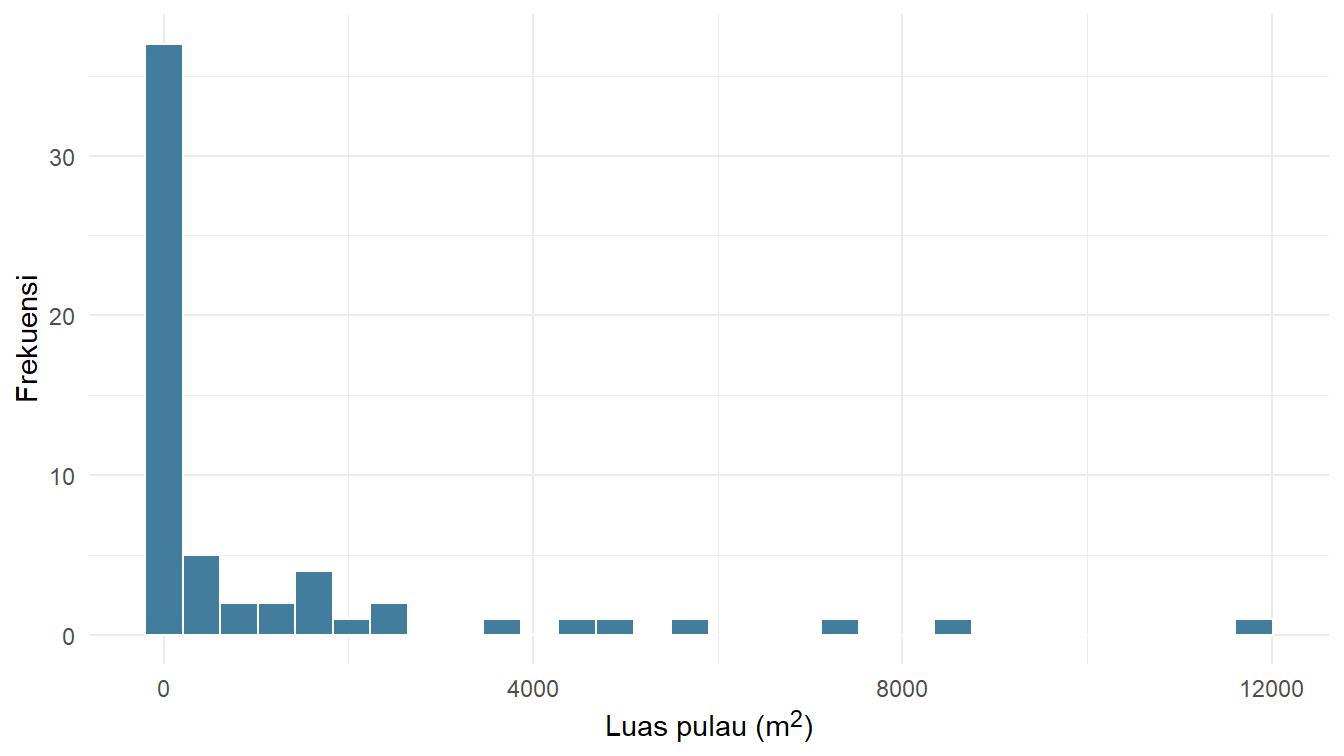
luas_pulau.
Bagaimana dengan distribusi banyak_spesies-nya? Silakan cermati Gambar 2.
data_pulau |>
ggplot(aes(x = banyak_spesies)) +
geom_histogram(
fill = "#9BBEC8",
color = "white"
) +
theme_minimal() +
labs(
x = "Banyak spesies",
y = "Frekuensi"
)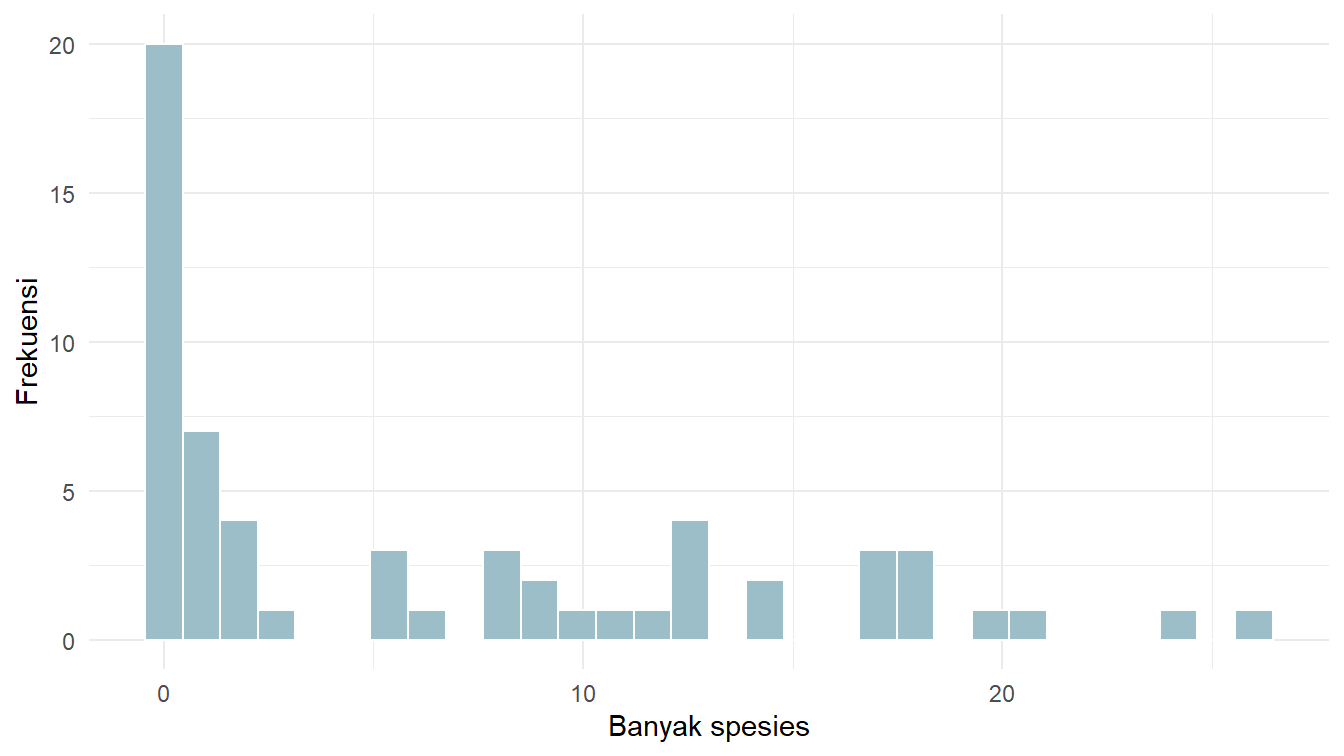
banyak_spesies.
Apakah terdapat hubungan antara luas sebuah pulau dengan banyaknya spesies yang tinggal di pulau tersebut? Untuk mengetahuinya, kita buat diagram pencar yang merepresentasikan hubungan antara luas_pulau dan banyak_spesies.
diagram_pencar <- data_pulau |>
ggplot(
aes(x = luas_pulau, y = banyak_spesies)
) +
geom_point(
color = "#427D9D",
size = 3
) +
theme_minimal() +
theme(
axis.title.x = element_markdown()
) +
labs(
x = "Luas pulau (m^2^)",
y = "Banyak spesies"
)
print(diagram_pencar)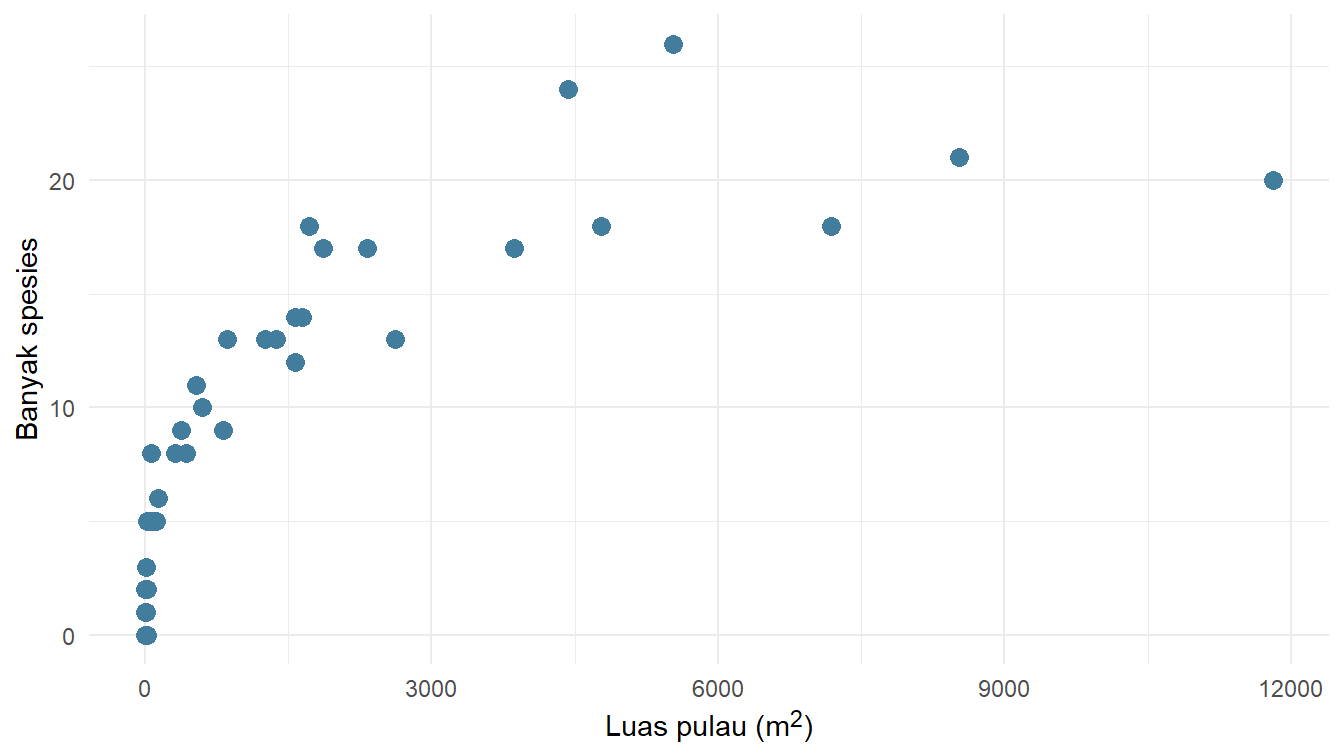
luas_wilayah dan banyak_spesies.
Gambar 3 menunjukkan adanya hubungan antara luas_pulau dan banyak_spesies. Semakin luas sebuah pulau, semakin banyak spesies yang tinggal di pulau tersebut. Lalu, bagaimana hubungan tersebut? Pertanyaan ini akan dijawab dengan melakukan pemodelan. Model yang akan kita pakai adalah fungsi linear, pangkat, logaritma, dan Weibull kumulatif. Keempat model tersebut masuk ke dalam dua kategori, yaitu model linear dan nonlinear.
Mengapa model linear digunakan di sini? Padahal titik-titik data pada Gambar 3 jelas-jelas tidak mengikuti pola linear. Model linear dimasukkan di sini untuk memberikan contoh pemodelan yang paling sederhana.
Pemodelan Linear
Model linear merupakan model yang sederhana dan mudah dilakukan. Untuk melakukan pemodelan linear, kita menggunakan fungsi lm().
Call:
lm(formula = banyak_spesies ~ luas_pulau, data = data_pulau)
Coefficients:
(Intercept) luas_pulau
3.662650 0.002549 Berdasarkan pemodelan linear tersebut, kita mendapatkan persamaan dengan konstanta 3,662650 dan koefisien variabel luas_pulau sebesar 0,002549. Visualisasi model linear tersebut disajikan pada Gambar 4!
Kode
diagram_pencar +
geom_smooth(
method = "lm",
formula = y ~ x,
se = FALSE,
color = "#164863"
) +
geom_richtext(
x = 9000,
y = 30,
label = "*y* = 3,662650 + 0,002549*x*",
hjust = 1,
color = "#164863"
)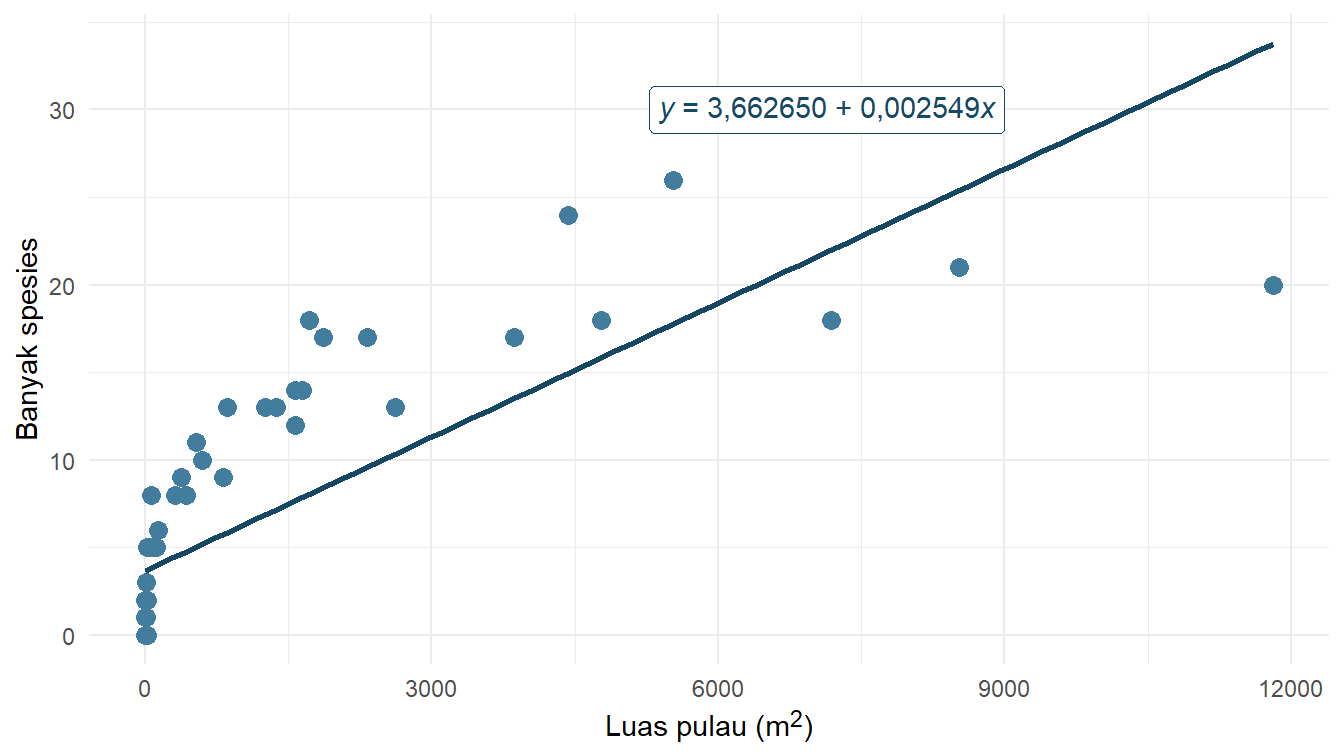
luas_wilayah dan banyak_spesies.
Pemodelan Nonlinear
Pada Bagian 3, kita telah memodelkan hubungan antara luas_pulau dan banyak_spesies dengan model linear. Sekarang, kita akan memodelkan hubungan kedua variabel tersebut dengan model nonlinear. Model nonlinear pertama kita adalah fungsi pangkat. Persamaan umum untuk fungsi pangkat ditunjukkan pada Persamaan 1.
\[ y = c x^z \tag{1}\]
Untuk melakukan pemodelan nonlinear, kita dapat menggunakan fungsi nls(). Fungsi ini membutuhkan nilai awal untuk \(c\) dan \(z\) pada Persamaan 1. Agar sederhana, kita pilih nilai-nilai awalnya \(a = 1\) dan \(z = 1\).
model_pangkat <- nls(
formula = banyak_spesies ~ a * luas_pulau^z,
data = data_pulau,
start = c(a = 1, z = 1)
)
print(model_pangkat)Nonlinear regression model
model: banyak_spesies ~ a * luas_pulau^z
data: data_pulau
a z
0.9239 0.3574
residual sum-of-squares: 306.5
Number of iterations to convergence: 17
Achieved convergence tolerance: 5.839e-06Dengan demikian, kita mendapatkan \(a\approx\text{0,9239}\) dan \(z\approx\text{0,3574}\). Model ini dapat ditunjukkan pada Gambar 5.
Kode
a_pangkat <- coef(model_pangkat)["a"]
z_pangkat <- coef(model_pangkat)["z"]
diagram_pencar +
geom_function(
fun = function(x) a_pangkat * x^z_pangkat,
color = "#164863",
linewidth = 1
) +
geom_richtext(
x = 8000,
y = 26,
label = "*y* = 0,9239*x*<sup>0,3574</sup>",
hjust = .5
)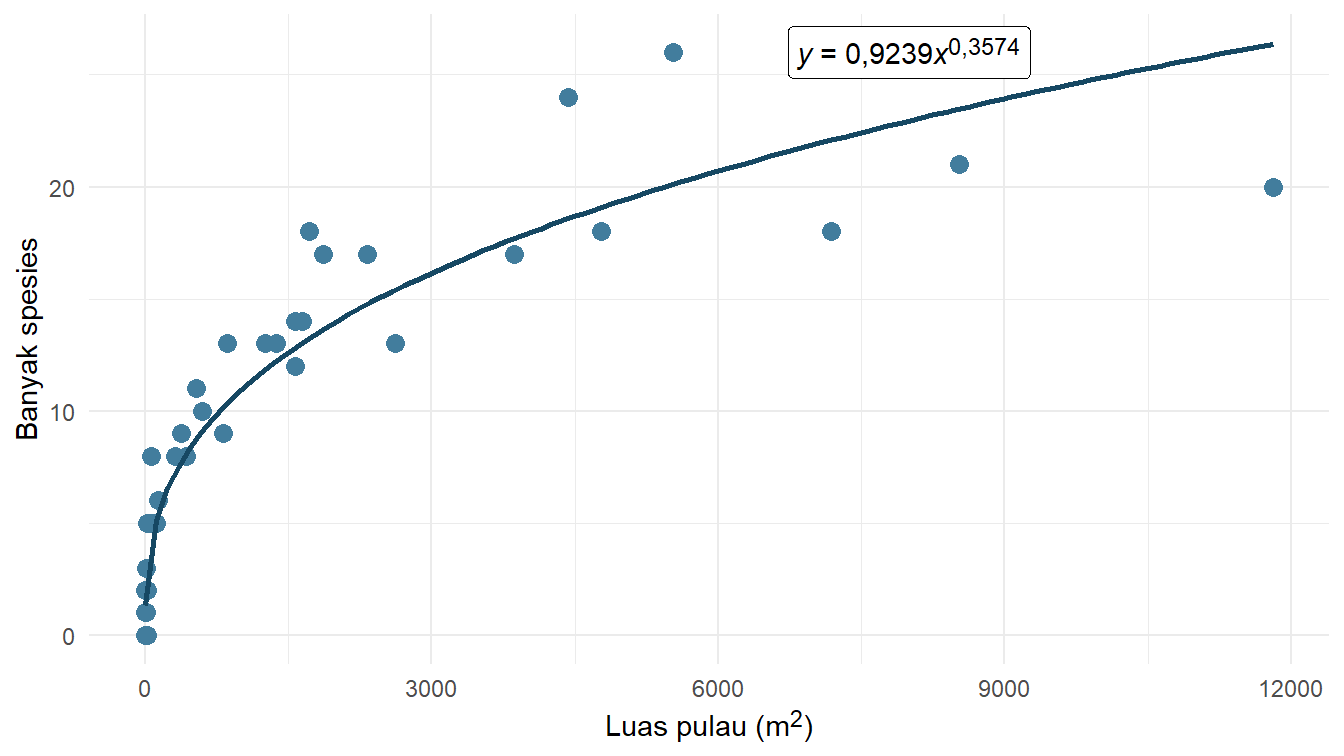
luas_wilayah dan banyak_spesies.
Kita lanjutkan pemodelannya dengan menggunakan model logaritma. Persamaan fungsi logaritma yang kita gunakan ditunjukkan pada Persamaan 2.
\[ y = c + z\log{x} \tag{2}\]
Kita menggunakan metode yang serupa dengan sebelumnya. Kita memanfaatkan fungsi nls() dengan nilai-nilai awal \(c=1\) dan \(z=1\).
model_log <- nls(
formula = banyak_spesies ~ c + z * log10(luas_pulau),
data = data_pulau,
start = c(c = 1, z = 1)
)
print(model_log)Nonlinear regression model
model: banyak_spesies ~ c + z * log10(luas_pulau)
data: data_pulau
c z
-5.347 6.228
residual sum-of-squares: 284.6
Number of iterations to convergence: 1
Achieved convergence tolerance: 1.058e-08Berdasarkan pemodelan tersebut, kita mendapatkan \(c\approx\text{-5,347}\) dan \(z\approx\text{6,228}\). Untuk melihat visualisasi model ini, silakan perhatikan Gambar 6!
Kode
c_log <- coef(model_log)["c"]
z_log <- coef(model_log)["z"]
diagram_pencar +
geom_function(
fun = function(x) c_log + z_log * log10(x),
color = "#164863",
linewidth = 1
) +
geom_richtext(
x = 12000,
y = 24,
label = "*y* = -5,347 + 6,228 log(*x*)",
hjust = 1
)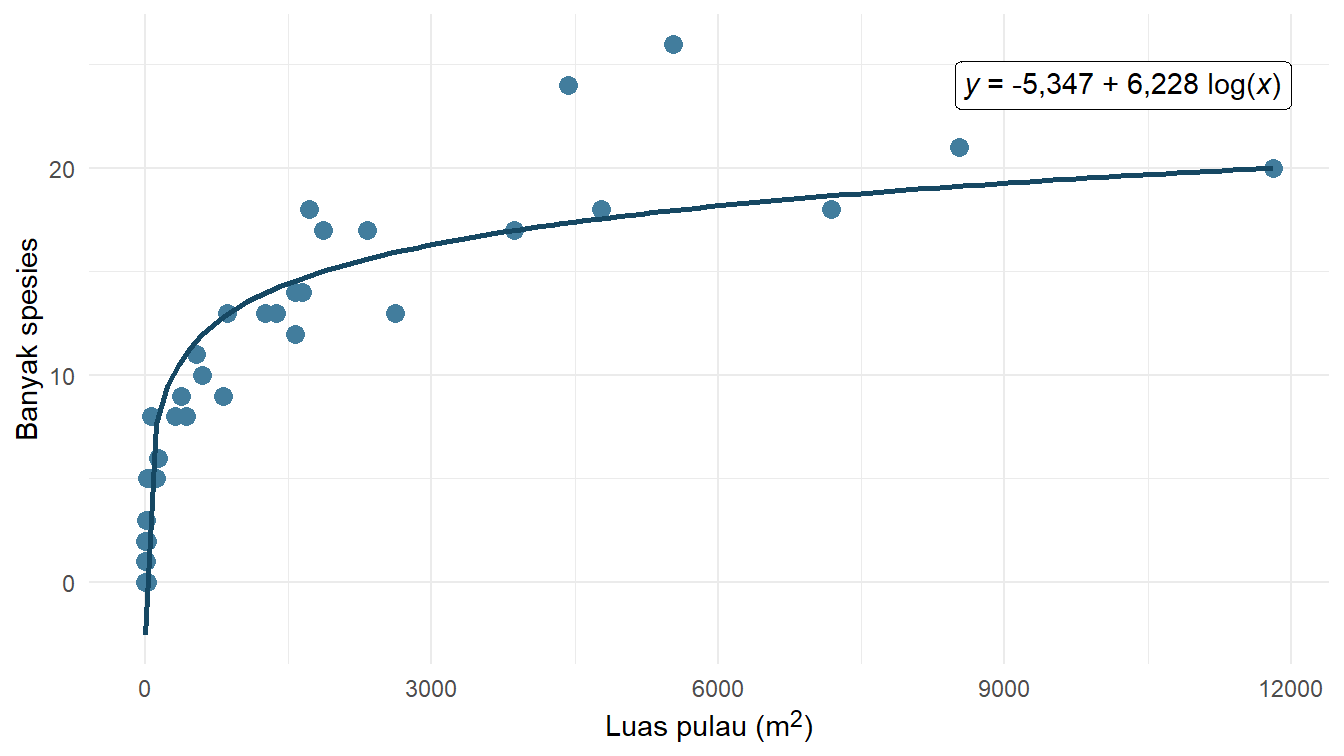
luas_wilayah dan banyak_spesies.
Sekarang kita melakukan pemodelan yang terakhir. Model yang kita gunakan adalah fungsi Weibull kumulatif. Persamaan fungsi ini ditunjukkan pada Persamaan 3.
\[ y = d \left( 1 - e^{-z x^f} \right) \tag{3}\]
Untuk menggunakan nls(), kita gunakan nilai-nilai awal \(d=1\), \(z = 1\), dan \(f = 1\).
model_weibull <- nls(
formula = banyak_spesies ~ d * (1 - exp(-z * luas_pulau^f)),
data = data_pulau,
start = c(d = 1, z = 1, f = 1)
)
print(model_weibull)Uh oh! Kita mendapatkan pesan error setelah menjalankan perintah-perintah di atas. Pesannya seperti ini.
Error in nls(formula = banyak_spesies ~ d * (1 - exp(-z * luas_pulau^f)), :
singular gradientApa yang salah? Kesalahannya terletak pada nilai-nilai awal \(d\), \(z\), dan \(f\) yang kita berikan.
Salah satu seni dalam menggunakan fungsi nls() adalah penentukan nilai-nilai awalnya. Nilai-nilai awal tersebut sebaiknya dipilih agar mendekati nilai-nilai yang sebenarnya. Untuk melakukannya, kita dapat memanfaatkan alat lain, misalnya kalkulator grafik Desmos.
Dengan menginputkan data yang kita punya, yaitu data_pulau, ke dalam kalkulator grafik Desmos, kita dapat memodelkannya. Tangkapan layar hasil pemodelan tersebut ditunjukkan pada Gambar 7.
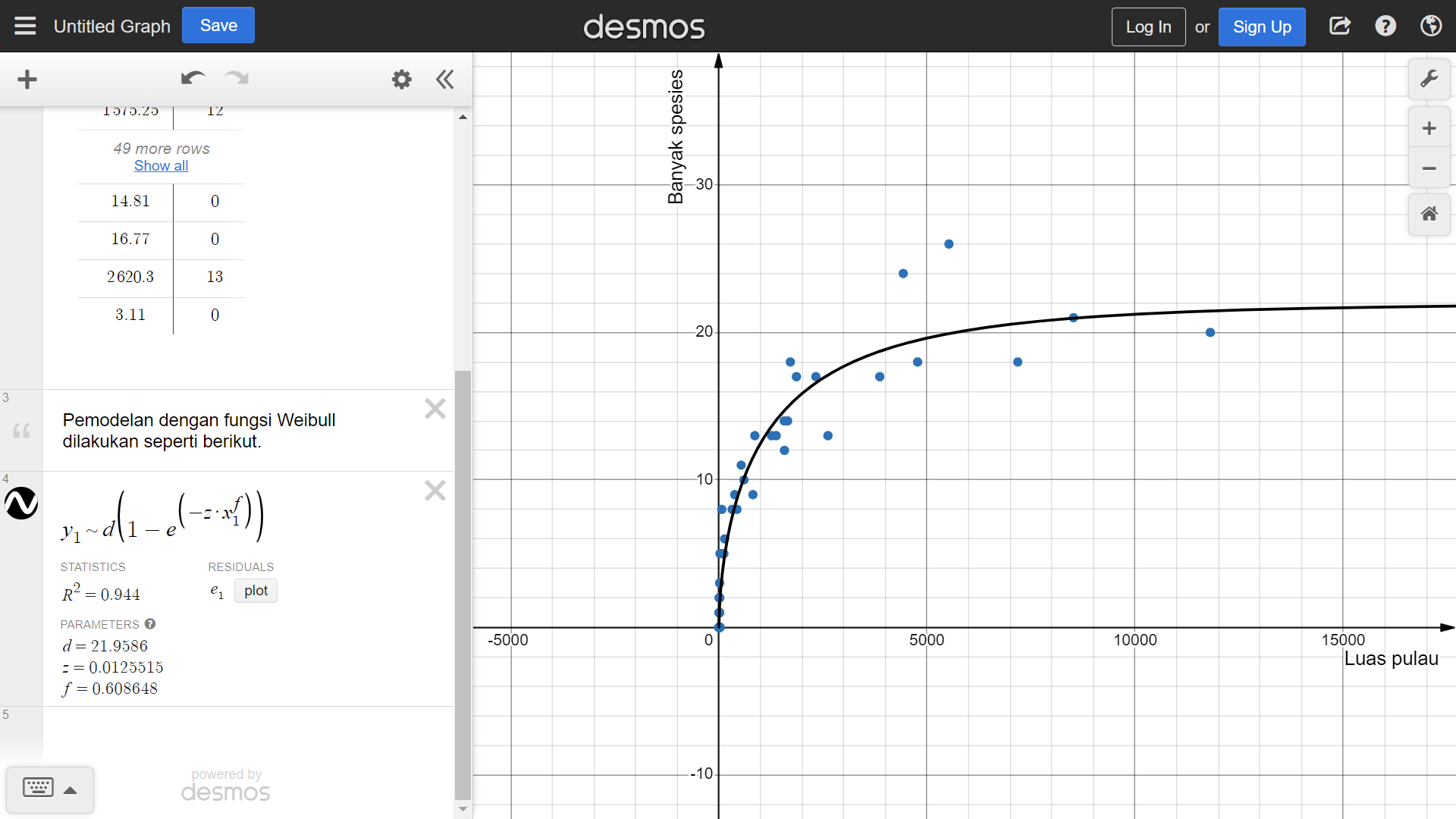
Pemodelan dengan kalkulator grafik Desmos tersebut menghasilkan \(d\approx\text{21,9586}\), \(z\approx\text{0,0125515}\), dan \(f\approx\text{0,608648}\). (Pemodelan tersebut dapat diakses melalui tautan ini.) Kita gunakan nilai-nilai tersebut sebagai nilai-nilai awal untuk nls().
model_weibull <- nls(
formula = banyak_spesies ~ d * (1 - exp(-z * luas_pulau^f)),
data = data_pulau,
start = c(d = 21.9586, z = 0.0125515, f = 0.608648)
)
print(model_weibull)Nonlinear regression model
model: banyak_spesies ~ d * (1 - exp(-z * luas_pulau^f))
data: data_pulau
d z f
21.95860 0.01255 0.60865
residual sum-of-squares: 186.3
Number of iterations to convergence: 0
Achieved convergence tolerance: 6.004e-06Untuk melihat visualisasi hasil pemodelan dengan fungsi Weibull tersebut, silakan perhatikan Gambar 8.
Kode
d_weibull <- coef(model_weibull)["d"]
z_weibull <- coef(model_weibull)["z"]
f_weibull <- coef(model_weibull)["f"]
diagram_pencar +
geom_function(
fun = function(x) d_weibull * (1 - exp(-z_weibull * x^f_weibull)),
color = "#164863",
linewidth = 1
) +
geom_richtext(
x = 12000,
y = 24,
label = "*y* = 21,95860(1 - *e*<sup>-0,01255*x*<sup>0,60865</sup></sup>)",
hjust = 1
)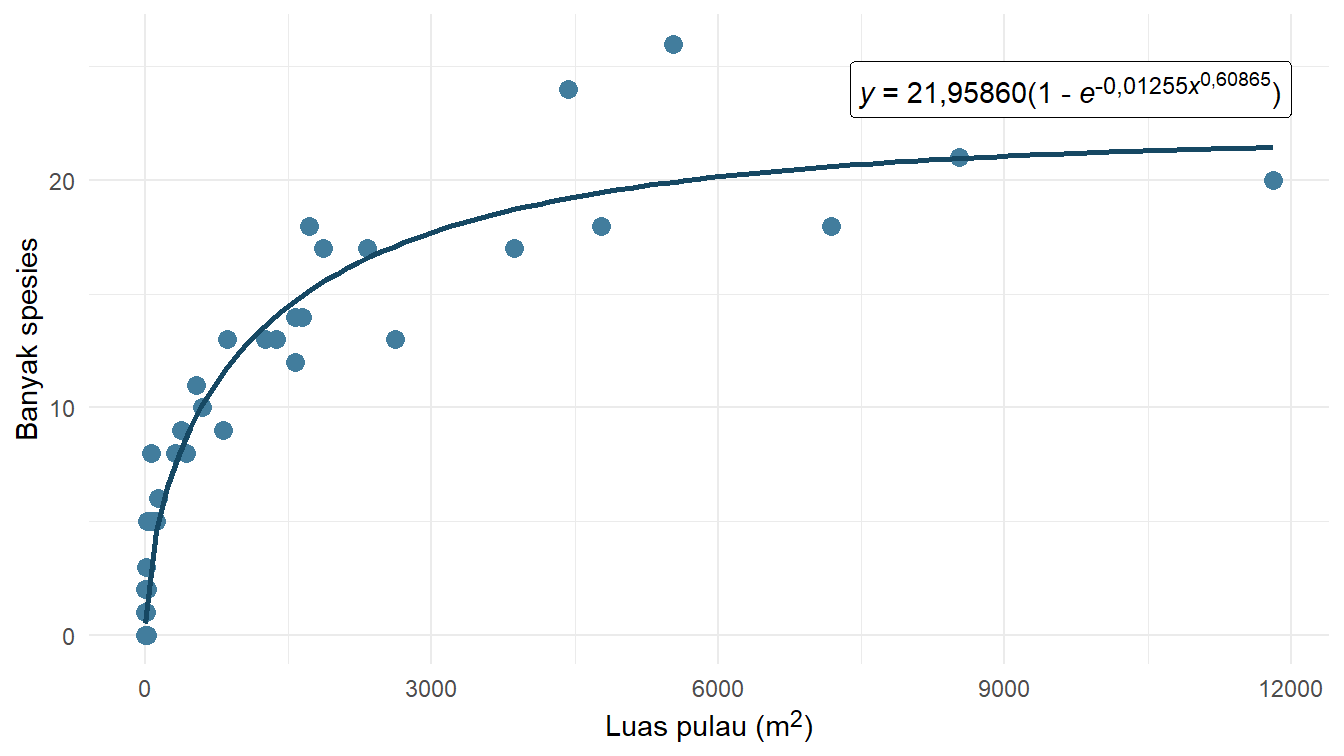
luas_wilayah dan banyak_spesies.
Mengevaluasi Model
Pada Bagian 3 dan Bagian 4, kita telah mendapatkan empat model untuk memodelkan hubungan antara luas_pulau dan banyak_spesies. Keempat model tersebut diringkas pada Tabel 1.
luas_pulau vs. banyak_spesies.
| Model | Persamaan |
|---|---|
| Linear | \(y = \text{3,662650} + \text{0,002549}x\) |
| Pangkat | \(y = \text{0,9239}x^\text{0,3574}\) |
| Logaritma | \(y = -\text{5,347} + \text{6,228} \log{x}\) |
| Weibull | \(\text{21,95860}\left(1 - e^{-\text{0,01255}x^\text{0,60865}}\right)\) |
Dari keempat model tersebut, manakah yang paling baik untuk memodelkan hubungan antara luas_pulau dan banyak_spesies? Untuk menjawab ini, kita dapat menggunakan akar kuadrat dari rerata galat kuadrat (root mean square error, RMSE).
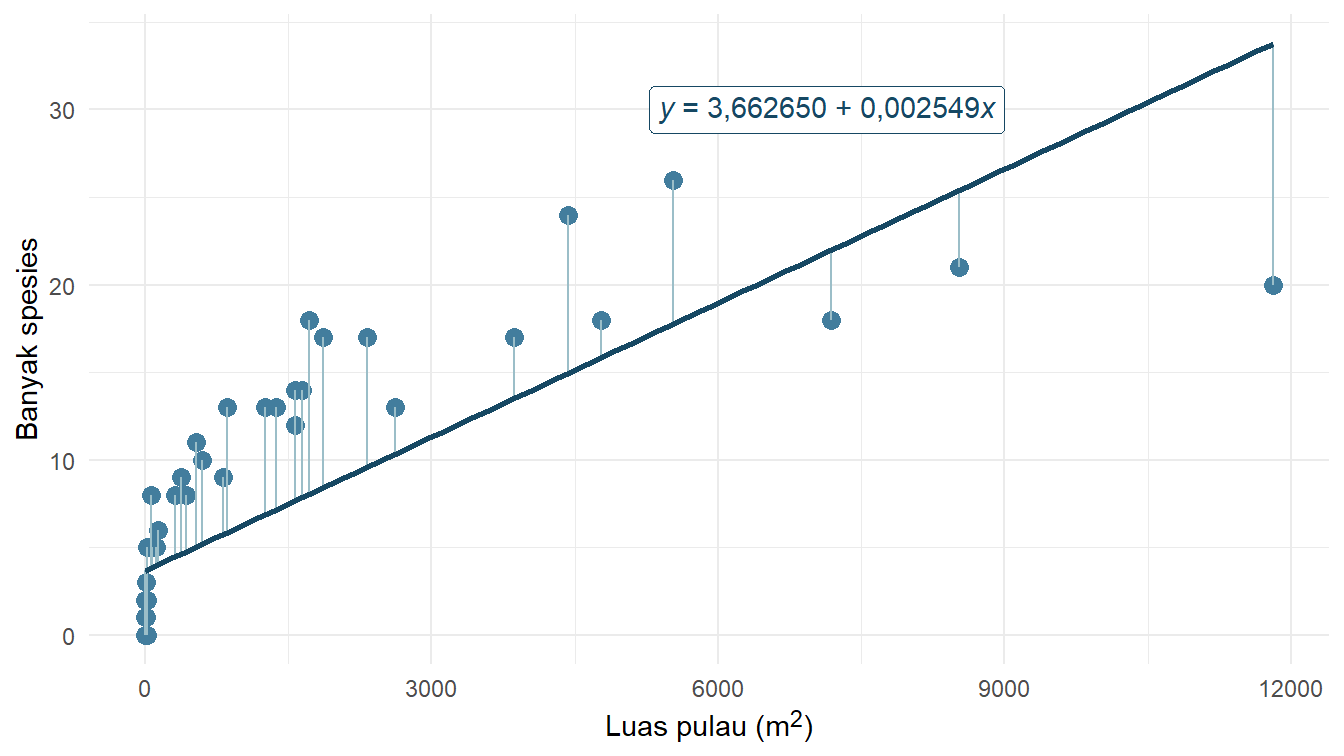
Untuk memahami RMSE tersebut, kita perlu mengetahui apa itu galat dari sebuah model. Galat merupakan selisih antara nilai sebenarnya dengan nilai hasil estimasi dari model. Untuk model linear pada Tabel 1, galat-galatnya direpresentasikan sebagai panjang ruas-ruas garis vertikal pada Gambar 9. Galatnya positif jika titik datanya berada di atas modelnya. Sebaliknya, galatnya negatif jika titik datanya berada di bawah modelnya.
Kode
est_spesies <- fitted.values(model_linear)
galat_linear <- resid(model_linear)
data_pulau_linear <- data_pulau |>
mutate(
est_spesies = est_spesies,
galat = galat_linear
)
diagram_pencar +
geom_segment(
data = data_pulau_linear,
aes(x = luas_pulau, y = banyak_spesies, yend = est_spesies),
color = "#9BBEC8"
) +
geom_smooth(
method = "lm",
formula = y ~ x,
se = FALSE,
color = "#164863"
) +
geom_richtext(
x = 9000,
y = 30,
label = "*y* = 3,662650 + 0,002549*x*",
hjust = 1,
color = "#164863"
)
Untuk mendapatkan galat-galat dari sebuah model, kita dapat menggunakan fungsi resid() atau residuals(). Dengan demikian, RMSE dari keempat model dalam Tabel 1 dapat ditentukan seperti berikut.
RMSE_linear <- sqrt(mean(resid(model_linear)^2))
RMSE_pangkat <- sqrt(mean(resid(model_pangkat)^2))
RMSE_log <- sqrt(mean(resid(model_log)^2))
RMSE_weibull <- sqrt(mean(resid(model_weibull)^2))
print(RMSE_linear)[1] 4.682503print(RMSE_pangkat)[1] 2.260007print(RMSE_log)[1] 2.177911print(RMSE_weibull)[1] 1.762084Untuk lebih mudah dalam membandingkan RMSE keempat model tersebut, kita visualisasikan nilai-nilai RMSE tersebut. Perhatikan Gambar 10!
Kode
rmse <- c(RMSE_linear, RMSE_pangkat, RMSE_log, RMSE_weibull)
nama_model <- c("Linear", "Pangkat", "Logaritma", "Weibull")
data_rmse <- data.frame(
model = nama_model,
rmse = rmse
)
data_rmse |>
mutate(
model = fct_reorder(model, -rmse)
) |>
ggplot(aes(x = model, y = rmse)) +
geom_col(
aes(fill = rmse),
show.legend = FALSE
) +
scale_fill_gradient(low = "#9BBEC8", high = "#164863") +
theme_minimal() +
labs(
x = "Model",
y = "RMSE"
)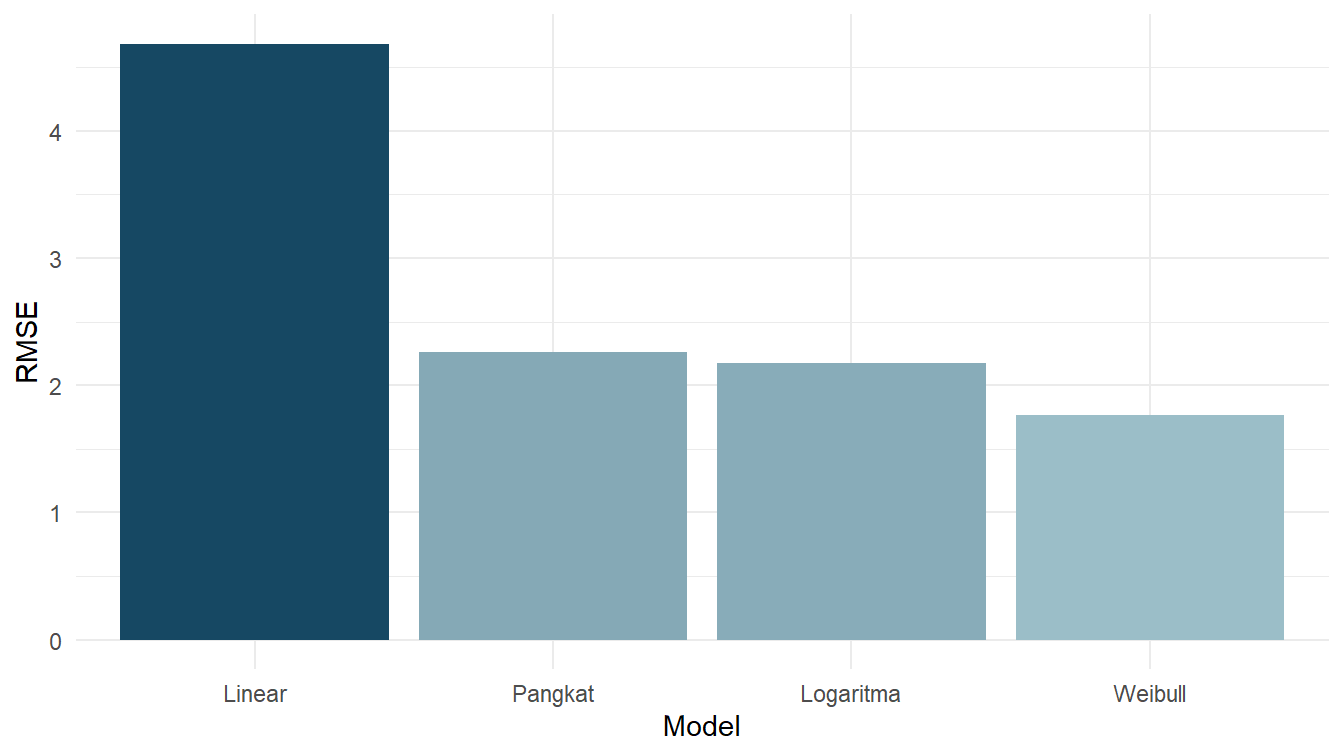
Model yang baik memiliki galat yang lebih kecil. Dengan demikian, semakin kecil RMSE sebuah model, semakin baik model tersebut. Berdasarkan Gambar 10, kita dapat melihat bahwa model Weibull merupakan model yang paling baik dibandingkan ketiga model lainnya.
Catatan Akhir
Banyak sekali set data riil yang dapat dimanfaatkan untuk keperluan pembelajaran Matematika. Artikel ini memperlihatkan bahwa set data tentang keanekaragaman tanaman berpohon di Kepulauan Raja Ampat merupakan salah satunya. Set data seperti ini tidak hanya berpotensi untuk membuat matematika semakin membumi, tetapi juga dapat menyadarkan peserta didik terhadap kekayaan alam Kepulauan Raja Ampat.
Secara lebih khusus, artikel ini mendemonstrasikan strategi untuk mendapatkan dan mengolah data tersebut hingga siap pakai. Strategi tersebut diceritakan mulai dari bagaimana proses penemuan data tersebut. Proses tersebut diceritakan pada Bagian 1. Setelah itu, data yang diperoleh juga perlu dikenali struktur dan isinya agar memudahkan kita dalam mengolahnya. Hal ini dipaparkan pada Bagian 2.
Pemodelan data juga telah didemonstrasikan pada Bagian 3 dan Bagian 4. Meskipun pemodelan dalam bagian itu dipaparkan secara ringkas, pemaparan tersebut diharapkan dapat memberikan gambaran umum tentang bagaimana memodelkan data, khususnya ketika kita menggunakan R. Terakhir, evaluasi model-model yang diperoleh juga telah didemonstrasikan secara sederhana di Bagian 5.